If Pre-training gave Akshara its knowledge and Mid-training gave it its professional structure, then Supervised Fine-Tuning (SFT) is the final high-stakes training that turns a model into a truly reliable assistant.
In this
Mid-training is the critical bridge that transforms a raw, next-token-predicting engine into a structured, instruction-following assistant.
For our Telugu model, nanochat-telugu-d20, mid-training was about more than just data—it was about shaping a
After perfecting our tokenizer, we reached the most compute-intensive part of the journey: Pre-training.
Pre-training is where the model "reads" the entire Telugu corpus and learns the statistical relationships between tokens.
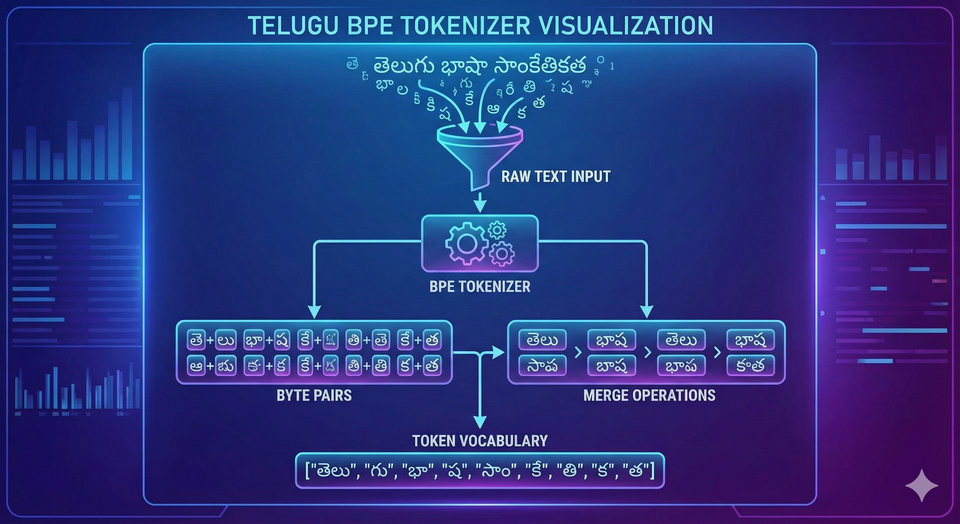
In the world of Large Language Models (LLMs), we often talk about parameters, FLOPS, and datasets. But there is a silent gatekeeper that determines how well a model "understands" a language
Do you know why we have so many new models for English or Spanish or Mandarin.
It's the data.
By now, the training recipes, models, architectures which work etc are all